
Llama3发布,GPT-5你到底在哪里呢?
2024-04-19
今天AI圈又迎来一件大事:Meta正式发布他们迄今最强的新一代开源大语言模型Llama3。
首批发布的Llama3 8B和Llama3 70B包括预训练和指令微调版本,8K上下文,在两个24K GPU定制集群上使用15万亿tokens数据训练而成,Meta称它们分别是80亿和700亿参数上最好的模型。同时一个参数超过400B的“最大Llama3”也在训练中,社区认为这个模型更恐怖,极有可能超过当前的闭源王者GPT-4 Turbo。
Llama3在各种行业基准测试中表现惊艳,广泛支持各种场景。接下来几个月,Meta将陆续引入新的功能,包括多语言对话、多模态、更长的上下文和更强的整体核心性能,并将与社区分享研究论文。
扎克伯格和Meta首席AI科学家Yann LeCun分别在Instagram和X宣布了这一消息。
网友们在评论区一片沸腾,马斯克前排回应:不错(有种淡淡的忧伤)。
我们赶快来看看Llama 3的具体性能表现:
多项测试成绩大幅超过Gemini 1.5和Claude Sonnet
Meta表示,新一代Llama3在Llama2 的基础上有了重大飞跃,确立LLM的新标准。在预训练和后训练过程上的改进大大降低了错误拒绝率,提高了一致性,并增加了模型响应的多样性。在推理、代码生成和指令遵循等方面都得到了极大改善,使得Llama3更加可控。
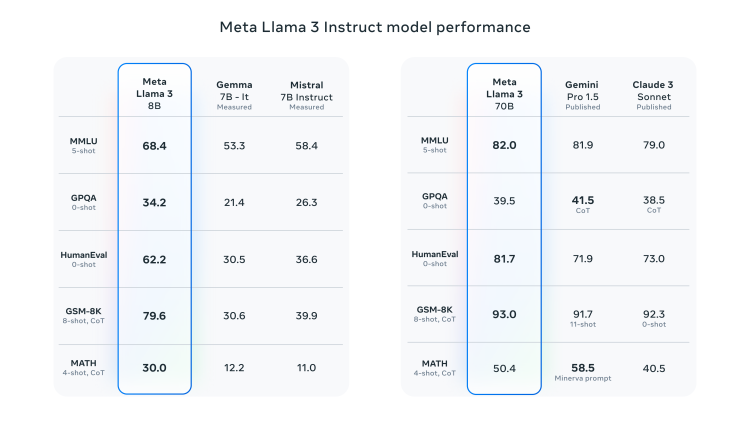
对照表中可见,Llama3 8B在大规模多任务语言理解、生成式预训练问题回答、编码和数学等LLM核心基准测试上都力挫Gemma 7B和Mistral 7B。Llama3 70B同样战胜 Gemini Pro 1.5和此前被夸爆了的Claude 3 Sonnet。
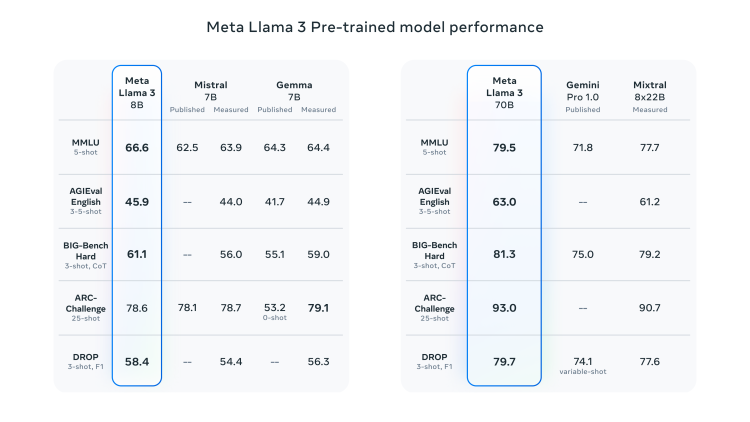
预训练版本的Llama3 8B和70B也在通用智能评估、困难任务、ARC挑战赛、DROP数据集上把Mitral 7B、Gemma 7B、Gemini Pro 1.0、新出的Mixtral 8x22B 打入手下败将之列。
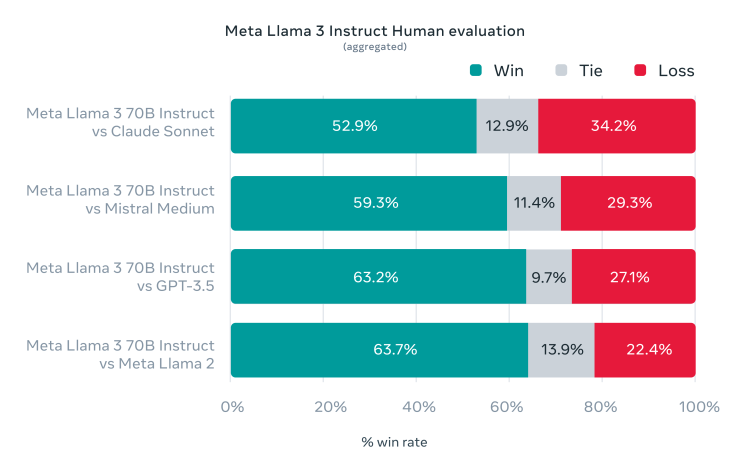
除了关注LLM标准基准测试项目, Meta还寻求模型在现实场景中的性能优化。为此,他们开发了一套新的高质量人工评估集。包含 1800 个提示,涵盖了“寻求建议、头脑风暴、分类、封闭式问题回答、编码、创意写作、提取、模拟角色/人物、开放式问题回答、推理、重写和总结” 这12 个关键用例。为了防止发生意外过拟合,即使是 Meta自己的建模团队也无法访问它。
在这套评估集上, Llama3 70B与Claude Sonnet、Mistral Medium、GPT-3.5 和上一代Llama2对战后胜率突出。(这里没有把GPT-4和Claude 3 Opus拉来对比,推测后续的400B模型将接过重任。)
Llama 3有哪些技术创新
Meta称,在Llama3的开发过程中秉承了创新、扩展规模和优化简洁性的设计理念。重点关注四个关键要素:模型架构、预训练数据、扩大预训练规模以及指令微调。下面分项来看:
模型架构
Llama3选择了一个相对标准的纯解码器Transformer架构。
相比Llama 2的改进之处有:Llama3使用一个包含128K tokens的分词器,可以更有效地编码语言,从而显著提高模型性能;在8B和70B两种规模上都采用了分组查询注意力(GQA)机制来提高模型推理效率;同时在8192个tokens的序列上训练模型,使用掩码确保注意力不会跨越文档边界。
训练数据
Meta认为训练出最佳LLM的关键是要整理一个大型高质量训练数据集,为此他们投入了大量资源:
Llama3在超过15万亿个公开可用来源的token上进行了预训练,比训练Llama2时的数据集足足大 7 倍,代码量是Llama2的4倍。其中超过5%来自高质量非英语数据,总共涵盖了30多种语言,以为即将到来的多语言使用场景做准备。
Llama3团队开发了一系列数据过滤管道来保证数据质量。他们还进行了大量实验,来评估在最终预训练数据集中混合不同来源数据的最佳方式,以此来选择一个包括STEM、编码、历史知识等等数据类别的最优数据组合,确保Llama3在各种使用场景中表现良好。
扩大预训练规模
为了更有效利用预训练数据,Meta针对下游基准评估开发了一系列详细的扩展法则,在实际训练模型之前就能预测最大模型在关键任务上的性能,来确保最终模型在各种使用场景和能力上都有出色的表现。
在Llama3的开发过程中,团队也对扩展行为有了一些新的观察。例如,尽管一个8B参数模型对应的最佳训练计算量是200B个tokens,但他们的8B和70B参数模型在接受高达15万亿个token训练后,性能仍然呈对数线性提高。
Meta结合了三种并行化方式:数据并行、模型并行和管道并行,来训练最大的Llama3模型。最高效地实现在同时使用16K个GPU训练时,每个GPU的计算利用率超过400TFLOPS。他们还开发了一个先进的新训练堆栈,可以自动进行错误检测、处理和维护,并进行了一系列硬件和可扩展存储系统的改进。最终使总体有效训练时间超过95%,与Llama2相比训练效率提升了约3倍。
指令微调方法创新
为了在聊天场景中充分释放预训练模型的潜力,Meta也在指令微调方法上进行了创新。后训练方法采用监督微调(SFT)、拒绝采样、邻近策略优化(PPO)和直接策略优化(DPO)的组合。在模型质量上的最大改进来自于仔细整理的训练数据,并对人工标注人员提供的标注进行多轮质量保证。
通过PPO和DPO从偏好排序中学习,也大大提高了Llama3在推理和编码任务上的性能。团队发现,当你问模型一个它难以回答的推理问题时,模型会产生正确的推理轨迹:知道如何得出正确答案,但不知道如何选择它。通过在偏好排序上进行训练,模型就能学会如何去选择正确答案。
哪里可以用到
根据官方介绍,Llama 3 将很快在所有主要平台上可用,包括云服务商、API提供商等。从AWS、Google Cloud、Databricks、Snowflake 、NVIDIA NIM到Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure——Llama3将无处不在。它也得到了AMD、AWS、Dell、Intel、NVIDIA和 Qualcomm提供的硬件平台的支持。
对于普通用户来说,最方便直接感受Llama3的方式就是通过Meta AI。
除了在WhatsApp、Messenger、Instagram、Facebook等应用与Meta AI聊天助手对话外,今天还推出了网页版。即开即用,可以输入文本提问来生成图片和简单代码,支持实时搜索,其它功能还不是很完善。如果想存储历史记录则需登录Facebook账号。
真正的“GPT-4级”开源模型就在眼前
而Meta透露,Llama3 8B和70B只是Llama3系列的开始,更多令人期待的东西即将到来。
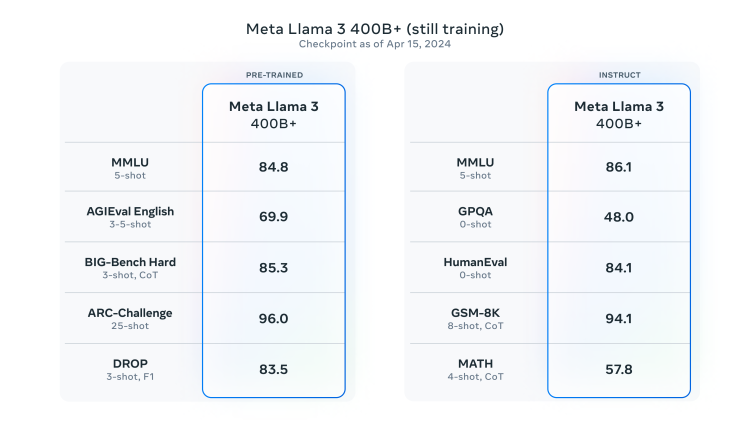
一个超过400B参数的最大模型正在训练中,开发团队对此感到兴奋。未来几个月,Meta将发布多个新功能,包括多模态、多语言对话能力、更长的上下文窗口以及更强大的整体能力。一旦完成所有Llama3的训练,他们也会发表一篇详细的研究论文供社区参考。
Llama3 8B和70B,加上一个证实了正在训练的400B大模型,无疑向开源社区注入一支超强兴奋剂。
而不久后即将发布的Llama3 400B+会有多厉害?
大神卡帕西给予了很高评价:“Llama3是Meta一个看起来非常强大的模型。坚持基本原则,在可靠的系统和数据工作上花费大量高质量时间,探索长期训练模型的极限。我也对400B模型非常兴奋,它可能是第一个GPT-4级别的开源模型。我想很多人会要求更长的上下文长度。”
同时他也提出了个人请求,希望能有比8B更小参数,理想规模在0.1B到1B左右的模型,用于教育工作、(单元)测试、嵌入式应用等。
英伟达高级研究经理Jim Fan认为,它将标志着社区获得对“GPT-4级别模型”开放权重访问的分水岭时刻,这将改变许多研究工作和草根创业公司的计算方法。
从当前预测数据来看,Llama3 400B+已经足以匹敌市场上最强大的Claude 3 Opus和GPT-4。而Llama-3-400B仍在训练中,有望在接下来的几个月中变得更好。“有如此强大的基础设施,可以解锁很多研究潜力。期待整个生态系统的建设者能量激增!”
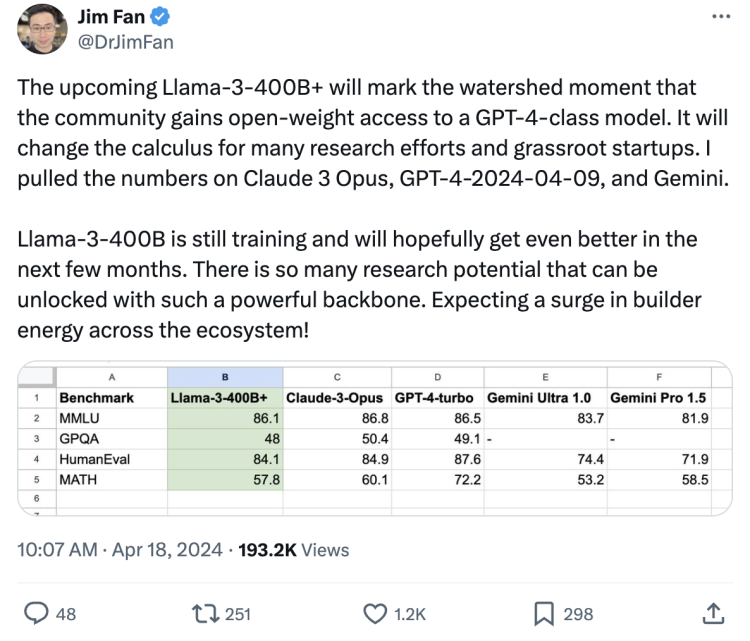
一个让所有人必须考虑的事实就是:开源模型追上闭源模型的历史时刻可能就在眼前了。
这对开发者可能意味着,AI应用可以更加快速地涌现和迭代出来。
而对创业公司们来说,则意味着更彻底的思路上的冲击。
它直接影响到所有以闭源模型API为核心的商业模式——既然免费的足够好用,为什么还要花钱呢?
更重要的是,如果连OpenAI、Google和Anthropic神秘的工具箱都不再高不可攀,那做一个比不上开源最强水平的闭源模型的意义何在呢?
最后还是不得不问一句:GPT-5,你到底在哪里呢?
©版权声明
本文转载自互联网、仅供学习交流,内容版权归原作者所有,如涉作品、版权或其他疑问请联系或点击删除。