
大模型未来发展:RAG vs 长文本,谁更胜一筹?
2024-04-19
当前,AIGC的迭代速度正以指数级的速度增长。2024 年 2 月,谷歌发布的 Gemini 1.5 Pro 再次将上下文刷新为 100 万 token,创下了最长上下文窗口的纪录,相当于 1 小时的视频或者 70 万个单词。
由于 Gemini 在处理长上下文方面表现出色,甚至有人高喊“RAG 已死”。爱丁堡大学博士付尧表示:“一个拥有 1000 万 token 上下文窗口的大模型击败了 RAG。
大语言模型已经是非常强大的检索器,那么为什么还要花时间构建一个弱小的检索器,并将时间花在解决分块、嵌入和索引问题上呢?”随着模型上下文长度的提升,一个问题也逐渐显现:RAG技术是否会被取代?
针对这些问题,我们邀请了产业界和学术界的朋友们共同碰撞思想,交流观点。他们分享了关于长上下文和 RAG 的看法,并对上下文长度是否存在摩尔定律展开了精彩讨论。同时,投资人与产业从业者也分享了长上下文及 RAG 如何赋能 AI 应用。
一、长文本 & RAG 发展近况
1. 长文本发展近况
随着大模型上下文窗口长度不断增加,各个厂商对于文本生成模型呈现出“军备竞赛”的态势。
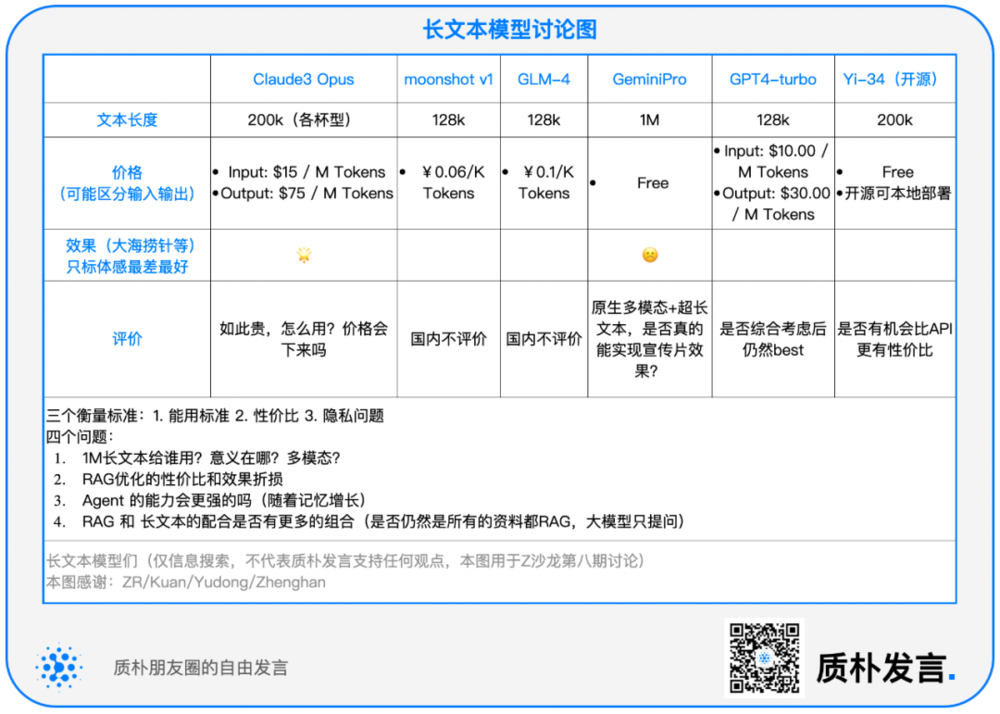
目前,主流的文本生成模型是聊天模型,比如GPT、Claude 3 等,也有少部分 Base 模型,例如 Yi-34 开源模型。
两位技术研究人员分享了他们对于大模型的看法:
-
用户使用最多的是 GPT,但对外开放的版本性能较差,用户交互端无法传输大文件,只能通过 API 接口上传。
-
月之暗面的 Kimi 模型大海捞针测试分数很高,但实际使用效果没有达到理想状态。
-
百川 192K 的闭源模型,对于 6 万字的长文本,其表现的推理能力和回答效果很优秀。
-
各种长文本的跑分数据,最高的是 Claude 3 模型。
2. RAG 发展近况
目前,大部分公司倾向于使用 RAG 方法进行信息检索,因为相比长文本的使用成本,使用向量数据库的成本更低。
而在 RAG 应用过程中,一些公司会使用微调的 Embedding Model,以增强 RAG 的检索能力;而有些公司会选择使用知识图谱或者 ES 等非向量数据库的 RAG 方法。
一个正常的模型使用 RAG 仍然是当前的主流选择。
由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。
在外挂知识库的过程中,Embedding 模型的召回效果直接影响大模型的回答效果,因此,在许多场景下,我们都需要微调 Embedding 模型来提高召回效果。
来自马里兰大学、劳伦斯利弗莫尔国家实验室、纽约大学的研究学者提出了一个大模型微调的方法;
在微调时只需要简单地在 Embedding 层上加随机噪声,即可大幅度提升微调模型的对话能力,而且也不会削弱模型的推理能力。
用 Alpaca 微调 LLaMA-2-7B 可以在 AlpacaEval 上取得 29.79% 的表现,而用加了噪声的嵌入则提高到 64.69%。不过该工作只在较小的模型上进行微调。
二、RAG vs 长文本,谁更胜一筹?
1. 观点一:RAG 与长文本各有所长
人们普遍认为将文本切片,然后进行相应的检索是最节省资源的方式。但因为检索是速度检索,受到阈值的影响,可能要多次反复检索,反而会造成一些 token 消耗的问题。
在多轮对话过程中,特别是在金融分析和客服场景,需要使用长文本来解决问题。如果进行切片处理,可能会丢失上下文之间的相互依赖关系。
对于大模型厂商,选择长文本或者 RAG 应该考虑哪种方式最节省 token。
一位投资人分享了一个项目:国内有一个做代码生成工具的公司,相比仅仅生成代码,他们更注重软件工程。
因为 GitHub 或 Copilot 生成代码分析和代码片段的能力已经很完美,国内真正需要解决的是能够围绕多个指标进行策略生成;
以操作系统为例,当我们想在操作系统中增加 AI 助手时,大模型不仅能实现底层部署,还能生成交互界面。
这种生成能力依赖于向模型输入的数据规模,可能涉及到的代码量会达到百万行甚至千万行。如果仍然使用比较原始的一次性输入方式,可能会遇到很多问题。
对此,这位投资人分享了两个观点:
-
长文本是一种智力能力。拥有一个更好的上下文窗口,可以更好地解决代码的相互依赖和逻辑性问题。
-
如果只是用 RAG 方式去分段代码,然后再连接起来,再分段提问,是无法满足需求的。
-
RAG 更像是能力的边界。如果只使用上下文窗口,而没有好好利用 RAG 基于检索的方式,很难解决同一个代码工程在多个模块,或者在多个功能上的问题。
-
只能解决比较局部的问题,无法处理多个模块之间的相互关联,例如进行联调测试,而合理使用 RAG 辅助可以拓展模型的知识边界。
对上述观点解释、拓展一下:
-
长文本是一种智力能力:从认知科学的角度看,人类处理长文本信息的能力是高级智力的体现。
-
阅读理解一本小说,写作一篇论文,都需要在大脑中维护一个宏大的上下文,同时进行逻辑推理、情节关联等复杂的认知活动。
-
这种能力区别于对简单句子或短语的机械处理。对语言模型而言,长文本建模能力意味着更强的抽象和归纳能力。
-
RAG更像是能力的边界:RAG 通过检索相关片段来辅助生成,在一定程度上弥补了语言模型在长文本建模上的不足。
-
它提供了一种即时获取背景知识的机制,减轻了模型的记忆负担,但它并不能取代模型本身的语言理解和推理能力。
针对代码生成,研究人员分享了一个最新技术:Task Weaver。Task Weaver 是微软的框架,用 GPT 的一个常规模型来完成的。
本质是把一个复杂任务拆成很多小部分,然后再把每个小部分再去做 code intervention,中间用代码的形式来交互。
在每一个小部分里面,开始套各种模板。这种用在长文本的话,可以解决掉内容丢失的问题。但是这个模型上下文不长,超过 8K 就结束了。
特别是它里面有个 Tools 叫 RAG,它占用上下文很大,每次调用 Tools,就会把 RAG 里面的东西全部抛进来,RAG 会作为一个 Tools 的 Observation 返回给 Agent。
之后,把整个 Agent 的结果成为下一个 RAG 的内容,在下一次 Agent 的时候再套,再把这个记录套回去。如果长文本技术的发展提升,Agent 上限可能会提高。
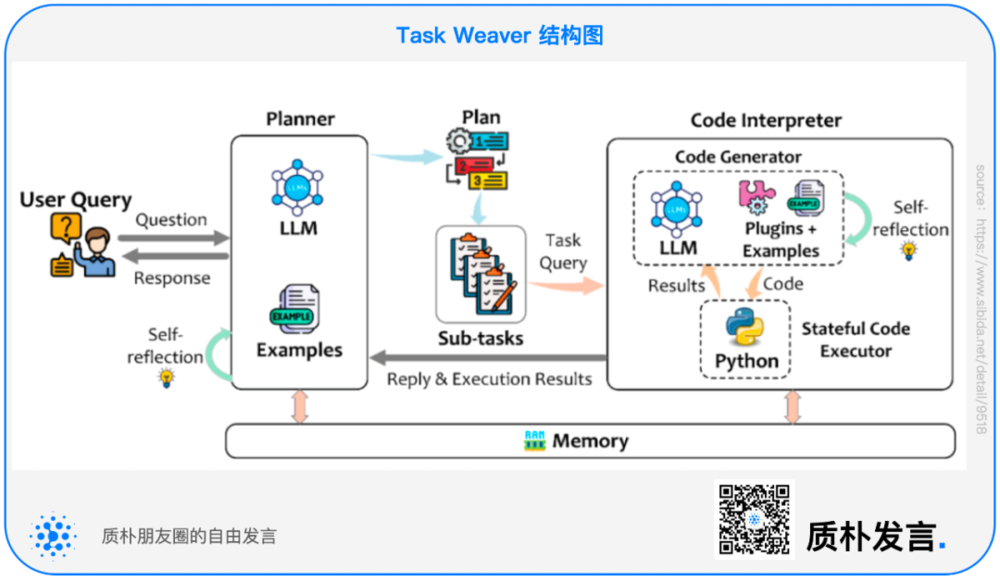
TaskWeaver 是一款代码优先的 Agent 框架,能将用户的自然语言请求转化为可执行代码,并支持海量数据结构、动态插件选择以及专业领域适应的规划过程。
作为开源框架,TaskWeaver 充分发挥了大语言模型的潜力,通过可定制的示例和插件融入特定领域知识,让用户能够轻松打造个性化虚拟助手。TaskWeaver 项目已在 GitHub 上开源,并于发布当日登上 GitHub 趋势榜。
2. 观点二:长文本将取代 RAG
引用付尧的观点,即长文本正在取代 RAG。长文本相比于 RAG 在解码过程中检索具有明显的优越性。
爱丁堡大学博士付尧在评价Gemini 1.5 Pro 的帖子中写道:
“一个有 1000 万 token 上下文窗口的大模型击败了 RAG。LLM 已是强大的检索器,那为什么还构建一个弱小的检索器并花时间在解决分块、嵌入和索引问题上呢?”
他表示,1000 万 token 上下文杀死了 RAG。(Twitter地址:https://twitter.com/Francis_YAO_/status/1758934303655030929)
虽然当前上下文模型的计算成本很高,上下文窗口的消耗成本和时间消耗是非线性增长的,但有人认为未来可能会有更好的方式来重复利用缓存,从而释放压力。
从 AI 的历史发展来看,现有模型的成本能降低 90%,RAG 可能会从现在的 50% 的应用场景缩减到 10%。
编者按:在大规模语言模型中,重复利用缓存是一种优化策略,旨在提高模型的推理效率和速度。
它的基本思路是:将模型在处理长文本时生成的中间结果(如隐藏状态、注意力矩阵等)存储在缓存中;
当遇到相似的上下文时,直接从缓存中读取这些中间结果,而不是重新计算。比较常见的是Key-Value Cache、Hidden State Cache 等。
对于长文本替代RAG,有人提出了一个很有意思的 idea:如果有一个无限长的上下文模型,直接将 wiki 里面所有的文本和相关信息全部输入,然后再去问问题。
实际上就相当于大模型直接做 RAG,不需要有任何外部的知识库,再去进行上游检索。模型的推理成本是个门槛,即模型输入的信息越多,模型推理的时间越长,成本越高。
但依旧存在可行的解决方案,即信息压缩:交给 RAG 或在线数据库处理的信息,本质上是可以被压缩的。
比如检查 GitHub 里的 Star 数量或者 wiki 上的访问量、贡献的数量等,都是可以被压缩的,进而转化为结构化的信息。
但此方法的前提条件是,需要找出哪些数据真的可以被压缩,并且它的压缩失真情况在接受的范围内。
3. 观点三:RAG 和长文本分工已经明确,不存在争议空间
对于一些严肃的场景中,如法规条文、保险或教育等,RAG 可以更好解决的问题。在进行向量化的初期,开发者设计的就是认为里面的内容是法定正确的;
或者至少为大模型提供向量数据库时,我们认为这些是客观事实,不应该对这些事实进行歪曲或改变。
如果将其交给大模型的幻觉或者概率去判断,实际上可能会出现问题。如果完全依赖长文本,结果一定是不准确的。
对于多轮对话的场景,RAG 能解决的问题并不是很清晰。如客服场景,很多大模型会出现与它对话的时候,会做一些后端的成本精简,不需要动用全部算力来解答一个问题。
如果反复去确认,要给一个真实答案,这个时候只能交给长文本去解决这个问题,而 RAG 只是去把它向量化。
此外,对于软件工程领域,涉及到代码的补全、翻译或重构时,输入 token 会非常大,只交给滑动窗口去处理,会存在理解的障碍。
编者按:Devin 是全球首个 AI 软件工程师,由公司 Cognition 推出。它有全栈技能,包括开发工具集,如 shell、代码编辑器、沙箱浏览器等,并能用它们来高效编程。
Devin 在经过长期的推理训练后,能够规划并完成复杂的任务,包括构建和部署应用程序、自主查找并修复 Bug、训练和微调自己的 AI 模型等。不过最近 Devin 又被曝光造假,震撼了整个硅谷。
4. 观点四:长文本和 RAG 需要结合
RAG的特点是准确、事实性和时效性。用 RAG 的方式,可以将原有系统的元素变成多维标签,甚至将系统本身做成一个端到端的向量,或是一个标签化的端到端的实体,以防信息损失。
但如果只用 RAG 的方法去做模型,可能在多轮对话后,它就不知道说什么了。长上下文在解决问题时,是一个泛化和上下文理解的过程,要避免信息丢失。
长文本和RAG 都比较依赖于上游检索的输出。如果大模型对上下文的容纳程度比较低,那对检索的要求就更高,必须把最重要的信息检索出来。
但是,如果大模型可以接受更多的上下文,那么对检索的要求就相对降低,而对数据准备的要求就会相对提高。
对于大模型厂商来说,无论是做大模型基座还是其他,未来最终都是要转向消费端。只有当消费端起来之后,大模型才可能有一个大的爆发。
从消费端来看,一般考虑的是成本性能、泛化能力以及信息丢失。在消费端应用的场景下,最终是希望成本越来越低,性能越来越快,泛化能力越来越强。
-
如果不能接受信息损失,需要在系统里面投入更高的 RAG 成本。
-
如果只是进行角色扮演,或者是给出一个笼统的回答,那么长文本比较合适。
长文本和RAG 的结合更像是一种趋势,在输入大模型之前,我们不仅可以通过向量库去做文本检索;
还可以通过一些 function 去获取更多的文本来做集中的召回,通过大模型做能力整合再做 RAG。长上下文能够代表所有情况,但 RAG 系统仍然会存在。
以大模型基座为例,我们觉得它最终在市场上的竞争方向有两个:
-
长文本
-
性能越来越好,可以远程部署
5. 观点五:RAG 是大模型发展的中间态,短期内长文本无法替代 RAG
无论是传统还是新架构,不断扩大模型的处理长度后,其性能必然会有所损失。目前的大模型而言,可能较合适的处理窗口是 4K 到 8K,因为预训练是在这个长度范围内。
RAG 相当于我们把模型的存储扩展到了无限,我们要做的是把有用的、最重要的信息给大模型。
因此,RAG 一定是很重要的,只不过它未来可能会有多种形态,不一定是现在这种大模型和向量检索分开的形态,它的形态可能会有所不同。
但是,这种通过一些方法提前对信息进行精炼和提取的思想,一定会在大模型的发展中长期发挥重要的作用。
长文本处理和RAG 这两个技术会共同发展。对长文本处理已经有一些优化的方法。比如,通过微调的方法把训练的参数量已经提升到了十亿或者是百亿;
在推理上的话,减少长文本的处理开销也有一些优化方法,比如 MIT 的韩松实验室有一个 Streaming LLM 的方法,可以识别出长文本中哪些是重点的 Context 或者 Token;
然后保留这些部分和最近的一些信息,可以进行推理长度的优化,从而降低推理的成本。
除了长文本处理在不断进步之外,RAG 最近也有很多新的技术,未来可能会结合 agent,在其他方面提高模型解决具体实际问题的能力。
来自MIT、Meta AI、CMU 的研究者提出了一种名为 Streaming LLM 的方法,使语言模型能够流畅地处理无穷无尽的文本。
使用 StreamingLLM,包括 Llama-2- 7/13/70B、MPT- 7/30B 在内的模型可以可靠地模拟 400 万个 token,甚至更多。
与唯一可行的 baseline——重新计算滑动窗口相比,StreamingLLM 的速度提高了 22.2 倍,而没有损耗性能。
以目前的推理成本来看,RAG 必不可少,可能会隐藏在产品里。比如说网易的逆水寒,它里面做了很多 AI 的具体应用,比如 NPC 对话。
MiniMax 的模型有一个功能叫做 Glyph,它可以去控制模型输出的结果,可以标准化它的格式,对于很多场景来说,它的推理是非常有帮助的。
逆水寒:《逆水寒》手游中的智能 NPC 系统,是利用网易伏羲 AI 技术,实装了国内首个游戏 GPT。这是一种基于深度学习的自然语言生成模型,可以根据上下文和输入,生成合理的文本输出。在游戏中,这意味着 NPC 不再是固定的对话框和任务分配者,而是可以与玩家自由对话,并且基于对话内容,自主给出有逻辑的行为反馈。
MiniMax 的限制返回格式(glyph):该功能可以帮助用户强制要求模型按照配置的固定格式返回内容。
三、上下文长度是否存在摩尔定律?
1. 观点一:存在
目前,上下文长度正在持续增长,并且其增长速度远超摩尔定律。如果按照 18 个月翻倍的标准来计算,从之前的几百万、几千万,到现在达到十兆;
上下文长度在一年内的变化就已经远远翻倍。这种增长速度本身就已经打破了摩尔定律所描述的增长曲线。
随着上下文长度的增长,算力将成为一个瓶颈。当所有的推理和训练任务都转移到处理上下文时,我们会发现仍然需要大量的能源。
以前可能只需要一张 A100 显卡,而现在可能需要一整台 A100 服务器才能完成任务。从产业界的角度来看,无论是算力还是能源,都会限制其增长速度。
因此,在考虑上下文长度增长的同时,还需要考虑到成本和资源限制的问题。
近日,Kimi 智能助手在长上下文窗口技术上再次取得突破,无损上下文长度提升了一个数量级到 200 万字。
从模型预训练到对齐、推理环节月之暗面均有原生的重新设计和开发。月之暗面认为,大模型无损上下文长度的数量级提升,也会扩大对 AI 应用场景的想象力。
包括完整代码库的分析理解、可以自主帮人类完成多步骤复杂任务的智能体 Agent、不会遗忘关键信息的终身助理、真正统一架构的多模态模型等等。
月之暗面创始人杨植麟表示:“上下文长度可能存在摩尔定律,但需要同时优化长度和无损压缩水平两个指标,才是有意义的规模化。”
2. 观点二:不存在
上下文的增长是包含了各个单元之间的逻辑关系,其复杂度的增长会高于计算能力的增长。
而且,现在大模型还是有非常多问题的,即使是顶尖的大型模型,在应用于工业产品时,也需要将需求范围缩小到非常具体的领域。
当需求被高度收敛时,相应的用户需求也会减小,这可能导致一种螺旋下降的趋势:投资减少,进一步导致研究和开发的动力减弱。
针对观点二拓展一下:
-
应用价值的不确定性:上下文长度的增加能带来多大的应用价值提升,还缺乏足够的实证支撑。
-
一些研究表明,过长的上下文能引入噪音,对模型性能的提升效果并不明显。如果投入产出不成正比,继续增加上下文长度的动力会减弱。
-
数据质量的瓶颈制约:高质量的长文本数据是上下文长度增长的基础,但现有的数据质量普遍不高,噪音、错误、不一致等问题严重。
-
数据瓶颈可能成为上下文长度增长的羁绊,单纯增加上下文长度而不解决数据问题,效果可能适得其反。
3. 观点三:不确定
摩尔定律是基于一段时间技术积累后观察到的规律,需要大量的资本投入和成本控制来驱动。
对于大模型和 RAG 这类技术,业界目前可能还处于探索阶段,从时间窗口来看还非常短暂,仅仅一两年的时间,并且没有大规模投入到特定场景中应用;
因此还没有足够的数据来进行经验总结。从这个角度来看,与晶体管发展的摩尔定律相比,上下文长度的增长规律还不够成熟。
四、模型层:大模型如何优化?如何有效对大模型测试?
1. 优化数据质量
在训练模型的时候,数据量并不是越大越好。真正重要的是训练数据的质量,而不仅仅是数量。使用 RAG 进行搜索的过程中,当数据量大了以后,它匹配出来的结果可能会有很多冗余。
比如,我们去搜索一个新的领域,不知道哪些文章是最好的,如果搜索出了 100 篇,不可能让模型全部去处理,需要加一些权重;
比如,文章的影响因子,或者是它的引用率、引用次数等,把这些因素考虑进去,然后对结果进行排序。
但这涉及到一些问题,有些优秀的文章并不一定引用率很高,特别是在一些特定的领域,它们可能引用的文章也相对较少。针对此问题,研究人员提出了一些想法:
-
学科的交叉会使得大模型效果更好。对于学科交叉的问题,最好的解决办法既不是依赖于长文本处理,也不是 RAG,而是微调。
-
在训练模型的过程中,我们需要考虑如何控制在各个大的领域里进行搜索。我们现在面临的是海量的文献,不可能把所有的数据都加进去,还需要人工智能来辅助。
-
现在面临的一个挑战,不仅要深度学习,还要广度学习,而且还要控制好搜索的范围,否则成本就会急剧上升。
-
我们的平台每天都有大量的科研数据,包括用户的行为数据和点赞数据等,这些数据对我们来说非常有用,当我们将这些数据纳入训练时,效果就非常明显。
-
所以现在的挑战是如何检索出大量的文本,并从中筛选出真正有价值的信息,将其他的信息过滤掉,然后再将这些信息放入模型中。
-
在应用层面,包括成本和产品质量,问题的核心在于是否需要数据的可靠性。如果要可靠的数据,就要使用 Agent。如果数据可以压缩或者有损,需要考虑其他的方法。
2. 节省计算资源
现在大部分模型,即使是长文本模型,在反向传播阶段,从第一步到最后一步文本窗口不可能一直保持很长。
一定是在最后的时候去解决这个问题,以节约计算资源。在科研中,我们接触到的预训练阶段的长度是 4K 或 8K。
学术界也有人提出,我们应该尽量让一个窗口内的数据尽可能相似,即在一个窗口或者一个数据条中,数据应该是相似的主题或内容。从论文来看,这可能对预训练有好处。
3. 大海捞针是否是唯一?
目前主流测试还是靠大海捞针,现在有一些新的测试,提出了一个更加复杂的大海捞针 Benchmark。
从产品侧,需要看受众端的用户。来自教育产品的从业者分享其观点:我们试过把哈利·波特做成一个鲜活的角色,帮助用户了解哈利·波特的内容。
但家长对于内容的真实性和准确性要求是很高的,我们的产品无法达到他们的要求,所以这个方案就暂时搁置了。
对于非家长的产品,用户直接面向小孩,这种精确度就比较适合孩子体验。所以,从应用侧来讲,测试大模型需要考虑受众端的内容。
来自情感陪伴的从业者分享观点:我们较关注用户的使用时长、满意度、分页系数等,对于不同的模型,我们直接进行AB 测试,哪个测试高,我们就会选择这个模型。
编者按:
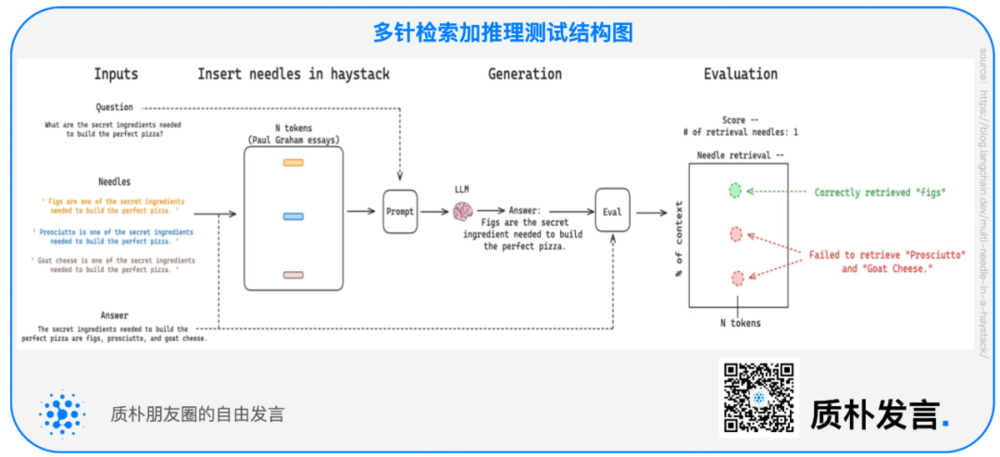
目前大海捞针广泛用于长文本测试,这种方法并不完全合理,尤其是对于需要检索多个事实并在此基础上进行推理的应用。
对此,研究人员提出了多针检索加推理测试,通过扩展 Greg Kamradt 的“LLMTest_NeedleInAHaystack”项目,以支持多针评估,评估工具使用了 LangSmith 。
五、长文本及 RAG 在大模型场景落地时的角色
1. 投资人的看法
投资人目前关注内存的增长。内存的增大使任务或应用有了更丰富的展现,从以前玩的简单游戏,到现在复杂的 3A 大作,上下文窗口的提升肯定能提升整个应用的能力。
RAG的外挂知识库可能是很重要的资产。有些人会把 RAG 或者留存下来的外挂知识库看作是没有长期价值的资产。
有些人认为 RAG 里面会留存下来一些有价值的东西,例如,对于某些客户或某一类行业的客户,会在库里面封装一些客户业务逻辑的知识。
将来去服务这一类客户,或者满足这个客户的长期需求的过程中,无论用哪个模型,这个模型是无法知道这些私密、个人化的信息或路径的。
这一部分对于公司将来能持续在这一类行业里面的交付能力,是有长期价值的。投资人会评估哪种行业能够留存下这方面的东西。比如代码生成能力,在不断地积累人和代码生成的监督过程中,RAG 里面留存下来的信息可以持续帮助到模型。
2. 情感陪伴
一位情感陪伴行业的从业者分享了他的观点:我们认为 RAG 是对 Long-Context 的补充,特别是对外部知识的补充。
如果没有 RAG,每次都需要将知识输入到上下文中,但上下文的长度有限,而且 Token 的使用也要成本。因此,RAG 可以使上下文的内容更丰富,同时节省成本。
在情感陪伴方面,为了让人物更加细腻,我们通常会使用prompt 来解决问题。在面向消费者的应用层面,将上下文和 RAG 结合在一起是每个人在情感上最需要的。
对于情感陪伴来说,回忆是非常重要的。如果能让上下文和 RAG 结合,直接作为大脑使用,那就达到了目的。
图片和其他角度可以增加想象力,就像微信可以发送图片、视频、语音和进行语音电话一样。这些功能对于微信的发展非常重要。
对于情感应用来说,如果你可以发送图片,然后你的朋友圈下面有人可以回复,这将为用户提供很大的情绪价值。目前,Agent 聊天仍然能够明显感觉到对方不是真人。
3. 教育产品
一位教育产品领域的从业者分享了他的见解:在教育产品中,我们需要打通孩子不同年龄段的信息,以提供更有逻辑性的服务。
比如,学龄前的一个产品,它的登录是通过家长的手机端的APP,就是他的微信和手机号。目前我们只能通过标签的方式把这件事给连接起来,但这种方式是比较低效的。
会场上一位专家提供了解决思路:可以采用特定的 Agent,比如 Read Agent,来处理这个问题。
他建议将 3-6 岁和 7-12 岁儿童的信息分别存储在两个数据库中,并使用大型模型对 3-6 岁儿童的信息进行总结,然后在每次需要读取时将其放入第二个数据库。
这种方法的核心是利用数据压缩技术,以提高处理效率。
Read Agent 是由 Google DeepMind 开发的一个类似人类阅读的 LLM 智能体系统,它能将有效上下文长度扩大 3-20 倍,同时取得更高的准确率和 ROUGE 得分。
Read Agent 系统通过三个主要步骤实现:
-
分割成片段,根据 LLM 的提示决定在连续文本中的何处暂停,形成片段;
-
摘要记忆,将每个片段压缩成更短的摘要,关联上下文信息;
-
交互查找,在给定任务和完整的摘要记忆中,决定查找哪些片段,将摘要与原始文本结合,解决任务。
ReadAgent 系统可以通过提示经过训练的 LLM 来实现。
4. 医疗领域
在医疗领域,大模型在理解文本和图像方面表现出色,但它们在 Mapping 上存在不足,传统的 RAG 和 Embedding model 可能效果不佳。
与医疗公司建立合作关系成为一种有效的解决策略。通过合作,让医疗公司在 Embedding 的过程贡献他们的算法;
包括他们对病例的诊断,将这些信息加到 Embedding 的工具库里,这些数据的向量数大致在百万到千万之间。同时,为保证技术真正应用,需找到有实际付费能力的客户。
有研究人员发现,引入了In context learning,可以显著提升了效果。以 COVID-19 的 X 光诊断为例,我们可以先向模型展示一些样本,包括阴性和阳性病例。
先给模型看一张阳性病例的图片,然后是阴性病例的。接下来,当模型再次看到新图片并询问其是阳性或阴性时,通过学习,判断效果会比无预先学习的情况下好很多。
相比于那些已经通过人工标注训练的模型,如果能够实现 CNN 方法,它可能会比使用 RAG 方法更加经济高效。
5. 未来发展趋势
随着视频和图像时代的到来,信息传递的方式将发生显著变化,这时传统的文本编码和解码方式将不再适用。
在这个新时代,Token 不再仅仅代表一个文字,而是可能代表更复杂的信息单元,因此传统的 NLP 方法将不足以处理计算机视觉领域的问题。
在算力方面,一些公司下一代的计算芯片放弃 GPU 架构,自己有一套硬件架构做深度学习,而且性能更高,耗电量会更少。
从 2014 年至今,谷歌已经构建了 6 种不同的 TPU 芯片。虽然单体性能仍然与 H100 差距明显,但 TPU 更贴合谷歌自己生态内的系统。
这也促使 Gemini 的内容生成速度非常快,虽然精度没有那么高,但生成速度远超 GPT 和 Claude。下图以 Gemini Pro 和 Claude 3-Haik 代码生成速度为例。
在谷歌发布 Gemini 大模型的同时,DeepMind 团队还写了 60 页技术报告阐述 Gemini 多模态的技术原理,报告提到谷歌用 TPU v5e 和 TPU v4 来训练 Gemini。
当日,谷歌还发布了 TPU v5p,称训练速度比前代快 2.8 倍,有望帮助开发者和企业客户更快地训练大规模生成式 AI 模型。
训练大模型需要大量的计算能力,因为它们通常在包含数十亿个单词的数据集上进行训练。
传统的CPU 和 GPU 架构难以处理这种计算负载,通常会减慢训练过程并限制大模型的功能。Google TPU 专门针对矩阵乘法和二维卷积进行了优化。
据谷歌的解析 TPU v4 论文,相较用英伟达 A100 构建的超级计算机,用谷歌 TPUv4 建的超级计算机速度快 1.2-1.7 倍,功耗降低 1.3-1.9 倍。目前,谷歌超过 90% 的 AI 训练都在 TPU 上。
©版权声明
本文转载自互联网、仅供学习交流,内容版权归原作者所有,如涉作品、版权或其他疑问请联系或点击删除。